Garbage collection
by Carl Burch, Hendrix College, November 2011
Garbage collection by Carl Burch is licensed under a Creative Commons Attribution-Share Alike 3.0 United States License.
Based on a work at www.cburch.com/books/gc/.
Contents
2. Basic algorithms
2.1. Reference counting
2.2. Mark and sweep
2.3. Copy collection
2.4. Generational collection
3. Real-world garbage
3.1. Collectors
3.2. Programming implications
1. Motivation
Much software is written without the availability of garbage
collection. C is an example of this: C programs that allocate
memory using malloc must deallocate it using free.
Whenever programmers allocate memory on the heap, they must carefully
track when the memory is being used, and the program must include an
explicit deallocation after the memory usage is complete.
If a program loses track of allocated memory without deallocating it, the program is said to have a memory leak. For long-running software, memory leaks are bothersome bugs: The program seems to work well, but it grows slower and slower over time — and, eventually, the system will allow no further memory allocations. Fortunately, there are tools that help to identify memory leaks, such as valgrind and Purify, but these programs only identify allocated memory blocks that seem to be inaccessible, and the programmer must then try to figure out how to modify the program so that the block is deallocated after its final use.
This technique of explicit deallocation leads to other problems in addition to memory leaks: A program might deallocate a memory block before it is actually finished using it, and the program would go on to use the memory even though it is deallocated — and by that point the memory might be used for other purposes. Alternatively, a program might end up deallocating the same block of memory twice, which can lead to problems of its own. Tools that identify memory leaks usually identify these problems as well.
Worrying about the lifetime of memory blocks can take a substantial portion of developer time. Naturally, many programmers regard this as a waste: Shouldn't the computer be able to figure out for itself when memory is no longer being used? This is what leads to garbage collection, which encompasses automatic techniques that a system includes for identifying the used memory and reclaiming all unused memory (garbage) for future allocations to recycle.
Garbage collection has been around since nearly the beginning of programming: LISP was one of the first programming languages (from 1959), and though it never achieved wide usage, it did include garbage collection. But early garbage collection implementations tended to be quite slow, and they often involved a program freezing in unpredictable situations while the system searched for memory to reclaim; this frozen time could even last for minutes. Most programmers disregarded garbage collection as impractical. But in 1995 the Java programming language was introduced with no memory deallocation mechanism aside from garbage collection, and programmers using it quickly found that it was practical despite this. Today, most new systems use garbage collection as a matter of course, though of course there are legacy systems (notably, those built in C or C++) where memory must still be explicitly deallocated.
2. Basic algorithms
Computer scientists have developed several basic techniques for garbage collection. As we'll see in Section 3.1, production-grade systems end up combining the techniques. But before we can examine production-grade systems we need to understand the basic underlying techniques. We'll examine four: reference counting, mark-and-sweep, copy collection, and generational collection.
2.1. Reference counting
In reference counting, the system includes a count for each allocated block of memory, which tracks the number of pointers referencing that memory block. In what follows, we'll imagine that each memory block is preceded by a four-byte header containing this count. Thus, if a program asks to allocate 12 bytes, the system would actually allocate an additional 4 bytes for this count (and probably an additional 4 bytes as a header containing information about the block, such as the block's length).
Confronted with a program, a compiler will
encounter an assignment statement such as
.
If r4 = r5r4 and r5 were integer variables that were
stored in registers,
then the compiler could translate this into a single assembly instruction
(on the ARM,
); but if MOV R4, R5r4 and
r5 are pointer variables, then a compiler using reference counting
would instead compile it to assembly code that accomplishes the following
steps:
- Increment the reference count for the memory block
referenced by
r5, since following the assignment there will be one more reference to that memory block. - Decrement the reference count for the memory block
currently referenced by
r4, since following the assignment there will be one less reference to that memory block. - If decrementing the reference count results in 0, deallocate
the memory block currently referenced by
r4. - Reassign
r4to point to the same place asr5.
For ARM's assembly language, such a compiler would translate
into the following code.r4 = r5
LDR R2, [R5, #-4] ; Increment r5's reference count.
ADD R2, R2, #1
STR R2, [R5, #-4]
LDR R2, [R4, #-4] ; Decrement r4's reference count.
SUBS R2, R2, #1
STRNE R2, [R4, #-4]
MOVEQ R0, R4 ; If count reaches 0, deallocate r4
BLEQ free
MOV R4, R5 ; Assign r4 to point to same place as r5.
Reference counting is a popular approach to garbage collection because it is simple, and because it aggressively identifies and deallocates memory that is no longer being used. That said, it suffers from three problems that lead system designers to seek alternative techniques.
With reference counting, each pointer assignment translates to several instructions to update the relevant reference counts. As we've seen on the ARM instruction set, an assignment might be done in a single instruction without garbage collection; but with reference counting, it ends up taking nine instructions. That's quite a performance penalty!
The reference counts add extra space that must be allocated for every block of memory. We were imagining an extra four bytes for the reference count — thus, if the program requests 12 bytes, we would actually allocate an additional overhead of 4 bytes for the reference count.
(You could imagine less that for bytes for the reference count, but you have to be careful about what happens if a block has more pointers to it than the count can contain. For example, if the reference count is just one byte, then what should happen when 256 different pointers reference the same block?)
Most crucially, the reference-counting technique doesn't actually work reliably! The problem arises when we have a cycle of memory blocks, each containing a pointer referencing the next one.
The following scenario illustrates: Suppose
r4points to a memory block that contains within it a pointer referencing a second memory block, which itself contains a pointer referencing back to the first. Suppose, moreover, that there are no other pointers referencing either of these blocks.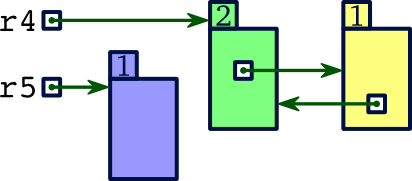
The reference count for the memory block referenced by
r4would be 2, since bothr4and the second memory block's pointer reference it. In the process of executing the assignment
, the computer would decrement this reference count to become 1.r4 = r5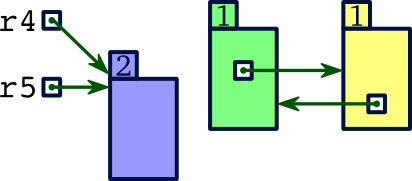
Since the reference count for the memory block previously referenced by
r4is still nonzero, it remains allocated. Nonetheless, it is no longer reachable. It is referenced by the second memory block to which it points, but that memory block isn't itself reachable from any of our variables. Even though both blocks should have been deallocated oncer4was reassigned, in fact both blocks will never be deallocated.Reference counting suggests no efficient way for identifying cycles like this. Nonetheless, such cycles commonly arise in real programs. Thus, any system that employs reference counting must use some other approach for avoiding or identifying cycles.
2.2. Mark and sweep
The mark-and-sweep algorithm for garbage collection involves periodically going through memory to identify all unused pieces of memory. Unlike with reference counting, pointer assignments happen by simply reassigning the pointer. But whenever not enough memory is available to satisfy an allocation request, we go through the following process to identify and reclaim all unused memory.
For every existing block of allocated memory, we clear the
mark
associated with the block. Themark
is simply a single bit, probably stored as part of the header describing the block. (Such a header is required anyway to indicate how long the block is — and thus where the following block can be found.)Now we go through and mark all memory in use. We do this by executing the below
markprocedure for each variablepthat points to memory in the heap.function
mark(p):
ifp's mark is 0:
Setp's mark to 1.
for each pointerqinp's block:
mark(q)This recursive algorithm manages to mark all blocks of memory reachable from any accessible variable. Thus, by the end of this step, all reachable memory has a
mark
of 1 in its header, while all unreachable memory has amark
of 0.For each block of memory whose
mark
is still 0, reclaim that block for use by future memory allocations.
The mark-and-sweep algorithm is intuitively simple, and it identifies all unused blocks of memory. It does have a notable disadvantages, though: The program must be frozen during the mark-and-sweep algorithm. The algorithm involves stepping through all memory blocks, and so it can take quite a long time. For a simple implementation, then, you'd find that the program would suddenly freeze while it attempts to find more memory to reclaim. The times when this happen appear to be unpredictably random.
(You might object that mark-and-sweep could be executed in the
background, as essentially a separate process that runs whenever the current process is idle. This would be nice, but unfortunately it doesn't work:
Suppose our program involves two pointers, p and q,
and q is the sole pointer to its block of memory, which we'll call B.
Now, let's suppose that the mark-and-sweep process is in the middle of its
marking step, having already handled p but not yet q
(and thus B remains unmarked);
and at this point the program ends up assigning
and p = q
.
Now the marking step might continue onto q = NULLq, but it won't
mark B, since q no longer points there.
Thus, B remains unmarked still, and it would be reclaimed for other purposes even though B is now reachable through p.)
Another problem with mark-and-sweep is that the recursion stack
in calling mark can get very deep. For example, if we have a
linked list with 10,000 nodes in it, then the stack for mark
would grow to include 10,000 nodes. This possibility of heavy memory
usage comes at the time that it can least be afforded!
2.3. Copy collection
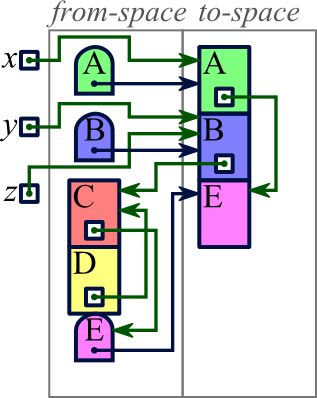
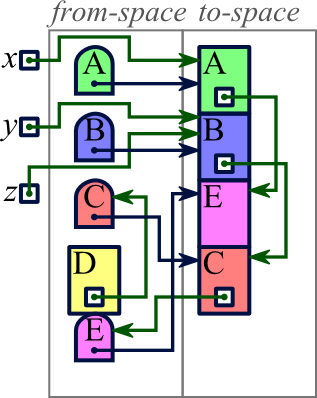
In contrast to the two techniques we have already explored, copy collection moves reachable memory blocks to different locations even as they remain in use. We imagine that memory consists of two halves, which we'll term from-space and to-space. All allocated memory will be in from-space; and when we allocate memory, we allocate in from-space. But eventually from-space will become full, and then we will start our copy collection.
The goal of copy collection is to move all reachable memory from
from-space to to-space. We start just with the blocks
referenced directly by a variable. Then we start iterating through
the blocks already copied into to-space; for each pointer within each
of these blocks, we copy the block referenced by it
(and modify the pointer to reference its new location). As we go
through this process, though, we will encounter some pointers referencing
blocks that have already moved; to deal with this, our process of
copying a block to to-space leaves a tombstone
behind at the
block's prior location in from-space, saying where to find the block's
new location.
We'll look at some pseudocode for accomplish this. First, we'll
define a function that finds a new location in to-space for its
parameter block a and returns this new location.
functioncopy_block(a):
ifareferences a normal block in from-space:
Letbreference allocated region of to-space large enough to hold block.
Copy block ataover tob.
Create tombstone ataholding new locationb.
returnb.
else:
return address in tombstone referenced bya.
We then go through the following procedure to complete the copy collection.
for each pointer variablep:
p←copy_block(p)
for each block in to-space:
for each pointerqwithin block:
q←copy_block(q)
The following example illustrates.
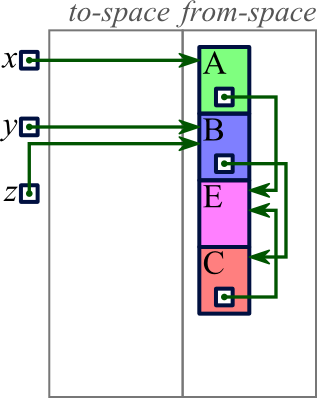
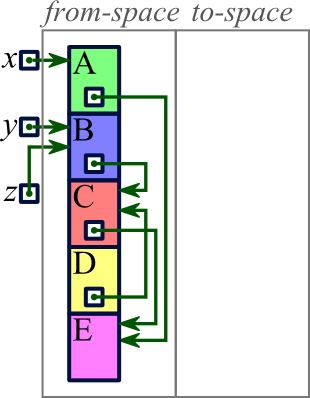 |
Our example supposes we have three variables (x, y, and z) from which we can access blocks in the heap. The heap contains five blocks as illustrated. All blocks are in from-space. |
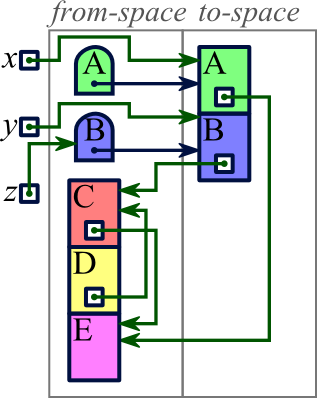 |
|
 |
|
 |
|
 |
|
Copy collection has some notable disadvantages. Most notably, by dividing memory into two halves and requiring all the usable memory to lie in one of the halves at any point in time, we have halved the amount of memory available. With an adequately-sized address space, this is not necessarily a huge problem, but it is certainly a notable issue.
Another major issue with copy collection is the same as for mark-and-sweep: The current program must be frozen while garbage collection is in progress. One reason is that in the middle of collection, some pointers reference tombstones, which would lead to complications if a program were allowed to access such a pointer. This might be resolved by including code for each memory reference to test whether it references a tombstone, though that would come at a performance penalty. Another problem is the same scenario that led to problems with programs running during the mark phase of mark-and-sweep; it would need to be addressed here as well if programs could run during the copy collection.
A final issue with copy collection — though this one can easily be addressed — is that the algorithm we described spreads related blocks out. In our example, blocks B and C were related (by a pointer from B to C), and they were adjacent in memory before the copy collection; but after the copy collection, we saw that they ended up being separated by another block. This behavior can lead to reduced performance with virtual memory, since B and C could end up on different pages. This possibility can be reduced, however, by modifying our program so that whenever a block is copied into to-space, we also copy all blocks referenced by pointers within that block (and perhaps also all blocks referenced by pointers within those blocks).
By contrast to these disadvantages, copy collection has a major advantage: Unlike any other memory management technique we have seen (explicit deallocation, reference counting, mark and sweep), copy collection compacts memory. This simplifies normal memory allocation tremendously: With these other techniques, a request to allocate memory would require searching through all the fragments of previously deallocated memory. But since copy collection compacts the used memory so that there is one huge chunk of free memory, memory allocation with copy collection has no fragments to worry about. The end result is that memory allocation can actually be faster with copy collection than it would be if programs explicitly deallocated memory.
Of course, you still have the time required to actually perform the copy collection. But there's a significant performance improvement here, too: Notice that copy collection only involves looking at the memory that is actually being used. In our example above, we never even looked at block D. If, then, our program happens to have many short-lived memory allocations, then each copy collection would only go through the few still-live allocations, and so it would complete quickly. And since memory allocation can go very quickly as well, overall the program could be faster than any other technique available.
While this is very promising, unfortunately the need to stop the program while iterating through all of used memory is a major problem. And it is the need to address this that leads to our next garbage collection algorithm.
2.4. Generational collection
Generational collection builds on copy collection by dividing
memory into many regions. Memory is always allocated into the first
region, and when it becomes full, we perform copy collection searching just through the first region to copy used blocks into
the second region. When the second region becomes full,
we perform copy collection just on this region to copy used blocks into
the third region, and
so forth. In this way, objects are born
into the first region,
and as it continues to live, it moves up through the regions. Thus,
we can think of each region as containing a generation
of
memory allocations, with each region have older memory allocations
than the previous one.
The advantage of this is that in practice, most memory allocations have very short lives, and so they rarely live long enough to be copied beyond the first region. When we perform copy collection, then, only a small number of memory allocations end up being copied into the second region, and so we don't need to perform copy collection even on the second region very often; and naturally we collect on the subsequent regions even more rarely. This means that when we collect garbage, we rarely need to go past the first region, which is quite small and can be collected quite quickly.
A difficulty arises in performing this garbage collection, though: To detect which memory in the first region should be copied into the second region, we must identify all pointers referencing any memory in the first region. Unfortunately, it's possible that there could be a pointer in one of the other regions that points into the first region. On the surface, then, it appears that the collection process must always iterate through all regions, which will take a lot of time.
We address this by observing that in practice, a memory block's pointers almost always refer to blocks that are older than the block (or roughly the same age). We only need to iterate through those very few pointers that reference blocks from younger regions. But how can we identify such blocks easily? One way is to divide each region into cards (512 bytes per card would be typical), and we can maintain a bit for each card signifying whether that card contains any pointers to a newer region. The copy collection process then would only need to walk through the cards that are marked — and in practice, very few cards would be marked, so this can go very quickly.
But how would a card become marked? As with reference counting, the system will need to insert code each time it compiles code for changing a memory value. In this case, the code set the relevant card's bit to 1 if the newly written value is within a younger region. This will slow the process of updating memory, but overall this would be much faster than going through all of the allocated blocks every time garbage collection occurs.
(By the way, for systems using virtual memory, we might choose cards to be the same size as pages. This would allow us to take advantage of the fact that the CPU automatically marks the card/page's dirty bit when it is changed. In such a system, we could then avoid the overhead for modifying references. That said, garbage collection is almost always part of a user process, and operating systems typically prevent user processes from being able to access the page table, so this possibility is more theoretical than real.)
Generational collection removes many of the problems with copy collection: First, we no longer have the problem of being able to use only half of memory. And usually collection can be quite fast, so that stopping the program during garbage collection isn't nearly the problem that it would be for copy collection or mark-and-sweep.
Nonetheless, generational collection still requires the program to be stopped during copy collection, even if it is for a short amount of time. More advanced approaches to garbage collection allow for garbage collection to proceed while the program runs, or at least attempt to reduce the time when the program must be frozen. They typically follow the basic outline of one of the basic algorithms we have examined, but with some difficult-to-understand subtleties. We won't examine such techniques here.
3. Real-world garbage
We've seen four basic approaches to garbage collection. But what happens in the real world? We'll see a summary of what some industrial-strength language implementations do, and we'll examine some implications for programmers.
3.1. Collectors
When programming languages are defined, designers rarely
specify exactly how to collect garbage; of course, they do
indicate whether garbage collection should occur, but they don't
constrain how it should take place.
Nonetheless, many programming languages have standard
implementations, and we can discuss how these implementations
collect garbage.
For Python, the standard implementation is CPython, which uses the reference counting technique. As we've seen, though, reference counting doesn't work for cycles of memory allocations that each contain a pointer referring to the next. CPython suggests that programmers should strive to avoid such cycles, but it also occasionally does something similar to mark-and-sweep so that such cycles can be detected and removed.
For Java, the standard implementation is the HotSpot JVM maintained by Oracle Corporation (before Oracle acquired Sun, it was by Sun Microsystems). It has gone through a variety of garbage collection techniques.
At Java's introduction in 1996, the earliest versions of the JVM used a variation of mark and sweep.
To improve performance, version 1.2 in 1998 switched to garbage collection based on dividing the heap into two: In the
young space,
it does copy collection, but after an object is copied between the two halves a certain number of times, it is moved into theold space
instead. Garbage in the old space is collected through a variation of mark and sweep.Subsequent versions of the HotSpot JVM included additional garbage collection techniques that a programmer could choose instead, but until Java 7 in 2011, the default garbage collection used this two-space technique.
In 2011, the default garbage collection algorithm switched to Garbage First. This is essentially a generational collector, though there are several enhancements like allowing generations to grow or shrink over time, and minimizing the length of the necessary pauses to the program.
Like Java, JavaScript implementations have evolved garbage collectors, too. The earliest implementation in Netscape Navigator 2.0 (March 1996) actually did no garbage collection: Memory allocated by JavaScript was simply kept around until the user navigated to a different page. This quickly proved inadequate, and Netscape Navigator 3.0 (August 1996) switched to reference counting. Early versions of Internet Explorer used mark and sweep. As JavaScript performance has become more important recently, browsers have become more sophisticated about their approach to garbage collection. Chrome, for example, now uses a generational garbage collection algorithm.
3.2. Programming implications
As programmers, fortunately, we usually don't need to worry much about garbage collection. It simply works. But there are some considerations we need to give our programs to allow the garbage collectors to do its job well. We'll examine each of these three points.
- Avoid unnecessary memory allocations.
- Clear references that are no longer useful.
- Consider weak references.
Avoid unnecessary memory allocations.
If you allocate more memory than necessary, then
the garbage collection will have to do more work with
identifying when memory can be cleaned up. As an example,
consider the following two fragments that both compute the
list of squares [0, 1, 4, 9, 16,... ].
| Fragment A | Fragment B | |
x = [] | x = [] |
The first fragment creates a new list with each iteration,
and makes x reference this new list instead; the garbage
collector is then relied upon to free the previous list.
By contrast, the second fragment creates a single list before
the for loop, and then that same list is slowly extended
to incorporate additional elements.
Admittedly, the biggest performance penalty for Fragment A is that each iteration must copy the contents of the list from one location to another. But an additional penalty is that the garbage collection algorithm must be more active in cleaning up memory from previous iterations. Both of these issues put together mean that Fragment A takes 314 milliseconds on a computer that can perform Fragment B in 20.4 milliseconds — the time is cut by a factor of 15 by this simple modification.
Clear references that are no longer useful.
As long as a memory allocation is reachable through any possible path,
the garbage collector will assume that the object should be kept.
However, a program might easily include some references
to blocks of memory that the program will actually never
access again.
A careful programmer will null out
any pointer
that will stay in memory for a while but no longer references
memory that is useful.
The classical example of this comes from implementing a stack. Following is a simple class definition.
class Stack():
def __init__(self, values):
self.contents = values + (100 - len(values)) * [None]
self.length = 0
def push(self, value):
self.contents[self.length] = value
self.length += 1
def pop(self):
self.length -= 1
return self.contents[self.length] # This leads to a memory leak!
Suppose we have an instance of Stack, and we use
push to add an object O to it and
then we use pop to remove that same object O.
Nothing in pop leads
the Stack instance's contents list to change,
so this list will retain a
reference to O until something else is pushed onto
the stack. During that time, O will not be eligible for
deallocation, even if there are no other references to O.
A good developer would ensure that this entry of contents would
become None, so that the Stack instance does not
prevent garbage collection of O from taking place.
This can be done by writing pop as follows.
def pop(self):
self.length -= 1
ret = self.contents[self.length]
self.contents[self.length] = None
return ret
Another example where this principle comes into play is in a program supporting multiple undo. This would typically be done by maintaining a list of actions completed by the user. The easy thing is to keep growing this list as long as the user continues doing new things; but this list can easily grow out of hand. It usually makes sense to start retiring things from the list once it grows to a certain size.
Consider weak references. Occasionally programs wish to retain a reference to a memory block without disqualifying it from garbage collection. We can do this using weak references. The following Python example illustrates how this works.
import weakref
data = Stack(['hello', 'world'])
dref = weakref.ref(data)
print(dref() is data) # displays "True"
print(dref().pop()) # displays "world"
data = Stack(['goodnight', 'moon'])
print(dref() is None) # displays "True"
print(dref().pop()) # exception: "'NoneType' object has no attribute 'display'"
In the first section, we create a Stack instance
referenced by the data variable, and the dref
variable contains a weak reference to this stack.
The weak reference is a bit odd in that you can't treat it
simply as a regular reference:
To pop from the stack, we must first call dref as a
function to retrieve a normal reference to the stack, and then
we call pop on that.
Thus, at the end of the section, you see dref().pop()
rather than dref.pop() as you would expect if dref
were a normal reference to a stack.
In the second section, we change data to refer to a
different Stack instance instead. At this point, there
are no normal references to the first Stack instance,
and so it is deallocated as garbage.
Consequently, calling dref() now returns None
rather than the normal reference it returned before.
Thus, calling dref().pop() attempts to call a member
function on None, which leads to an exception.
(Java supports weak references, too, through its
java.lang.ref package.)
It must be admitted that weak references aren't often used in regular programming. However, they can be useful. Here are two places they can be useful.
Suppose we have a long-running graphical program. Well-designed graphical programs typically include an underlying model object containing the data being edited and view objects that handle how to present that data graphically. The model is written so that it contains no dependence on the graphical presentation. Instead, it is designed so that it accepts abstract listeners to be notified whenever the model is changed. Each view will register itself with the model as a listener.
Now suppose in the course of running the program, the user often opens new windows and closes them, and that some of these windows have their own views of the same model, and so these views register themselves as listeners of the model. We can hope that the programmer would be very careful to un-register the listeners. But in practice it could make sense for the model to remember its listeners using weak references, so that when a window is closed, the view can possibly be deallocated, and the listener can be removed automatically.
Suppose we have a function that takes an object as a parameter and performs a complex computation based on it. We might hope to save recomputation by caching the return value, so that a later invocation of the function can simply find the return value in the cache rather than recomputing it. If we use a dictionary mapping each parameter object encountered to the computed value, then each parameter object will never be eligible for garbage collection even if there are no other references to the object. We can allow garbage collection of these objects by instead using weak references for the keys in the dictionary. The
weakrefmodule supports this through itsWeakKeyDictionary(and Java supports this through itsWeakHashMapclass).
Garbage collection is an important and complex feature of many modern programming languages. Fortunately, programmers rarely need to worry much about exactly how it works, but nonetheless there are occasions when understanding garbage collection can allow much better performance.