Principles of operating systems
by Carl Burch, Hendrix College, November 2011
Principles of operating systems by Carl Burch is licensed under a Creative Commons Attribution-Share Alike 3.0 United States License.
Based on a work at www.cburch.com/books/os/.
Contents
2. Interrupts
2.1. Interrupt categories
2.2. Handling interrupts
2.3. System calls
2.4. Library functions
3. Linux file-handling
3.1. Managing descriptors
3.2. Reading and writing
3.3. Examples
3.4. Default descriptors
4. Processes
4.1. Process table
4.2. Context switching
4.3. Preemption
4.4. Process scheduling
5. Linux process management
5.1. Creating processes
5.2. Running programs
5.3. A simple shell
In modern computing systems, the operating system is the foundational piece of software on which all other software is built. Its duties include handling communication with computer hardware and managing competing demands of other programs that are running. In this document, we'll study the fundamentals of how operating systems work, and we'll learn how programs can interact directly with the Linux operating system.
1. Purpose
So let's start with the basics: What is the operating system's purpose?
- It abstracts complex computer resources.
For example, a disk is a complex physical device that allows a system to read and write blocks of data of a kilobyte at a time (or four kilobytes on some newer disks). With each access, the disk must be told the specific physical location on the disk that it should access. This procedure is extraordinarily inconvenient for the typical program that wants to read or store a sequence of bytes. The notion of a file is more convenient for such programs; the operating system allows the program to regard storage on disk as a set of files, each a stream of bytes. The hardware itself is completely unaware of such a thing as a file: It is an abstraction created by the operating system to simplify how a program might deal with a disk.
The file isn't the only abstraction provided by an operating system. Other abstractions include the process for a running program, a window for access to a graphical display, or a connection for network communication. None of these abstractions has any basis in hard reality. But providing these convenient abstractions frees the programmer from worrying about the details of how the hardware actually works and from negotiating with other programs about what program has which rights.
- It provides hardware compatibility.
Everybody knows about the incompatibility issues surrounding operating systems, which cause people to have to use different software versions on different operating systems. Operating systems actually reduce incompatibility problems, though; we don't notice this because they eliminate incompatibility problems so effectively. For example, there are many types of storage (hard disks, USB flash drives, CD-ROMs); and even if you just look at hard disks, there are many standards for hard disks. Without an operating system, each program would have to include code to support each possible device. One program would be compatible with one set of disks, while another would work with a different set of possible disks. With operating systems, the OS gets the responsibility for supporting this variety of disk types, and any program can use any disk supported by the operating system. If somebody releases a new type of disk, only the operating system needs to be updated so that all programs can use the new disk.
- It protects the system.
If every program ran native on the computer, then each program would be able to wreak havoc with the system. One of the duties of the operating system is to stand guard over programs. It prevents individual programs from accessing the system directly, instead requiring any requests to go through the operating system. The operating system ensures that program requests are safe before executing them.
Part of this is to avoid malicious attacks, like those of a virus. But, just as significantly, it protects the system from permanent damage by errant programs, which perhaps haven't been tested fully yet.
You can think of an operating system as the adult in the computer, parenting the young user programs. An adult often has to explain events at the kid's level using metaphors (those are the abstractions), and the adult often performs tasks that the child can't handle on its own (buying a piece of candy).
2. Interrupts
To study how operating systems work, we need to understand a feature found in CPUs called the interrupt.
2.1. Interrupt categories
In the normal flow of a program, the CPU usually executes one instruction and then continues to the next one. Sometimes the CPU will encounter a branch instruction that leads it to jump to a different instruction; or it might encounter an instruction that calls a subroutine. This is all within the normal flow of a computer executing a program.
But there are exceptions to these rules, called interrupts, that lead the CPU instead to pause its normal program flow and jump instead into executing different code. The code executed in response to an interrupt is called interrupt handler, and it is an essential piece of the operating system. (The interrupt handler is always part of the operating system — not part of whatever program the CPU might have been executing at the time of the interrupt). Usually, but not necessarily, the operating system's interrupt handler will return to the instruction following where the CPU was at the time of the interrupt.
There are three types of interrupts: hardware interrupts, exceptions, and software interrupts.
A hardware interrupt is initiated by a device like a keyboard or hard disk. The system is wired so that such a device can send an electrical signal into the CPU, which upon witnessing the electrical signal initiates the interrupt process. The operating system's interrupt handler then manages communicating with the device appropriately to receive whatever information it has available (like which key was pressed or the data found on the disk) before returning back to the computation that was occurring before the electrical signal was received.
(While some hardware devices communicate with the CPU via interrupts, others do not: For these devices, the operating system must periodically query the device about whether it has any new information to report. This alternative design is called polling. Polling requires less electronic support than interrupts, but it is also inefficient, since the operating system must often execute code for polling only to find that no additional information is available. This can be especially problematic when systems have a wide variety of devices attached, all of which must be polled. With interrupts, the operating system does not have to do any work interacting with a device until the device has information to provide.)
An exception is a different type of interrupt which is initiated by the CPU. An exception arises when the CPU reaches an instruction that it does not know how to handle. For example, a CPU might encounter a instruction to divide two integers, but the second integer turns out to be 0; or maybe it encounters an instruction saying to load from memory even though the memory address is outside the bounds of available memory; or maybe it encounters an instruction that doesn't conform to the acceptable instruction format. In any of these cases, the CPU triggers an exception rather than complete the instruction, and the operating system's interrupt handler can react appropriately to the situation. Quite often, the operating system's response will simply be to kill the process, probably displaying a message to the user cryptically explaining that something weird happened.
(By the way, a CPU exception is not exactly the same as an exception that arises in a programming languages like Python or Java. Based on the previous paragraph, you might think that a CPU's exception for dividing by 0 leads to a programming language exception. More typically, when a Java compiler compiles code involving division, it inserts code to check whether the divisor is 0 before the instruction to actually perform the division; if it is not zero, then it continues to executing the division instruction. But if the divisor is zero, the generated code triggers a divide-by-zero exception for the program, thus avoiding the case that the CPU might raise its own exception and send control into the operating system.)
Finally, a software interrupt is initiated explicitly
by the running program using a special-purpose instruction
designed specifically for triggering interrupts.
In the ARM instruction set, this instruction is named
SWI;
it stands for SoftWare Interrupt, not
switch as you might otherwise assume.)
SWI #1This instruction is useful for transferring control into the operating system. For example, a program cannot save something to the disk directly; if it wants to do this, it must ask the operating system to do this. We'll see more about this in Section 2.3.
2.2. Handling interrupts
A modern CPU allows code to be executed in different processor mode, which provide different privileges for accessing the system. Most programs execute while the CPU is in user mode. User mode is very restrictive: For example, the CPU will refuse to execute any instruction for communicating directly with a device, because such access could allow the program to access data that it shouldn't. When in user mode, the CPU also restricts memory accesses to the small fraction of memory that is actually dedicated to the current program. By contrast, the operating system runs in supervisor mode, which allows direct communication with devices and permits access to all memory addresses.
But the CPU doesn't know this distinction between regular
programs and the operating system; all it knows is the current mode,
which it knows from the value of a register (which for the ARM is
a hidden
register called CPSR).
Of course, when the CPU is executing in user mode,
there must be some way to switch into supervisor mode,
since programs will want to communicate with devices like the disk.
But the CPU can't include an instruction that simply allows
changing the mode: Such an instruction would permit malicious
software to obtain untrammeled access to the system.
So how can the CPU allow switching into supervisor mode without
a simple instruction allowing this switch to take place?
The solution to this is the software interrupt. Whenever an interrupt occurs, the CPU changes into supervisor mode at the same time that it jumps into code that could only be part of the operating system. Because the CPU only enters supervisor mode at the same time it jumps into the operating system, a user-mode program has no way of tricking the CPU into executing its own code with supervisor privileges. (The CPU also allows the operating system to indicate the region of memory that a user-mode program can access; this allows the operating system to forbid user-mode programs from modifying the operating system.)
The ARM processor actually supports six processor modes, but we'll
concern ourselves only with these two: user mode and supervisor mode.
These two modes have different R13 and R14 registers;
when the CPU is told to access R13 (or R14),
it accesses one or the other
version of R13 depending on which mode it is in.
When an ARM CPU encounters a SWI instruction,
it goes through the following steps.
It copies the program counter
R15into the supervisor mode's link registerR14. This is so that when the operating system finishes processing the interrupt, it knows where to return.It copies the value of
CPSRintoSPSR.The
CPSR(from current program status register) is an additional register beyond the 16 general-purpose registersR0throughR15that are accessible by normal instructions. TheCPSRholds information about the processor state, including the four flags set by arithmetic instructions such asCMP. It also includes some bits indicating which of the six modes the processor is currently in; whenever the processor is told to execute an instruction that requires privileged access, it examines these bits ofCPSRto determine whether to execute the instruction or to raise an exception.The
SPSR(from saved program status register) is yet another register beyond the 16 general-purpose registers. It is unavailable when in user mode. It is used simply to saveCPSRso that it can be restored when returning back into user mode.The lower five bits of
CPSRare changed to 10011, the code the ARM processor uses to indicate that it is in supervisor mode.One bit in
CPSRis the interrupt flag. It indicates whether the CPU is to ignore interrupts received from I/O devices. This bit is normally clear so that the CPU heeds hardware interrupts, but theSWIinstruction will set the interrupt flag. This prevents the CPU from responding to other interrupts received while the operating system is processing the software interrupt.Finally, the address 8 is placed into
R15, so that the next instruction executed by the CPU will be the instruction in address 8 of memory. The instruction placed at this address would have been placed there by the operating system as the beginning of its interrupt handler, so that the CPU's next instruction will be from the operating system's handler.
2.3. System calls
A system call is a request by a user program to the operating system to perform some operation on the program's behalf. Examples of system calls in a typical operating system include a request to open a file, a request to start another program, a request to send a message to another computer, or a request to display a line on the screen.
As we'll study it here, we'll specify which system call we are making
through the argument to the SWI instruction.
Linux has assigned a unique identifier to each
system call type. The below table shows some of these codes.
Linux system call codes system call identifier exit1 read3 write4 open5 close6
Thus to make the exit system call, we'd execute
the instruction SWI #1. Recall from our earlier discussion
of the SWI instruction that we never saw a time that the CPU
actually examines the argument (#1 in
).
In fact, the processor ignores this argument when executing the instruction.
However, the interrupt handler (starting at memory address 8)
can determine the value of this argument by loading the SWI #1SWI
instruction into a register and retrieving its bottom 24 bits.
The following code loads this argument into R3.
MOV R3, [LR, #-4] ; load SWI instruction into R3
BIC R3, R3, #0xFF000000 ; clear top 8 bits, where SWI op code was
System calls will usually have parameters; a program should place
its arguments into the registers R0 through R3
just as it does when calling subroutines. On completing the system
call, the operating system leaves any return value in register R0.
As an example, let's look at the exit() system call with
Linux. The exit() system call is for telling the operating
system to remove the requesting process from the system entirely. It
takes a single integer parameter, an integer code that is meant
to summarize whether the process
was successful. Most often, this is simply 0, which conventionally means
that the process completed its job successfully.
Below is a simple C program using the exit system call
and its translation into ARM assembly using the system call conventions
described here.
int main() {
exit(0);
}main MOV R0, #0 ; place parameter into R0
SWI #1 ; enter OS with code 1 = exit
In the case of exit, there is no point in having
additional code following the system call, since the function will not
return to the user program.
Note how the assembly translation places 0, the system call's parameter,
into R0, and then it initiates the software interrupt using 1
for the system call code.
2.4. Library functions
When we write a C program, the system calls look mysteriously like calls to standard functions. Does this mean that all the functions we've learned about in C are system calls?
No. For example, printf() is a library
function. This means that it is included in a library for the
compiler to use, but it is not part of the operating system like a
system call. When the compiler compiles the program, it finds whatever
library functions the program uses and includes them in the executable
file. Thus, printf() is not part of the operating system; it is
part of the user program.
Library functions serve two main purposes.
- They provide portability.
Programming language designers want programs written in their language to be written across multiple platforms. Therefore, the designers choose to design their own functions, requiring the compiler for each platform to include an implementation of the functions. This way, a program written using these functions should work on many platforms. Thus, a program using
printf()can work on a wider variety of systems than one usingwrite().- They provide complex functionality.
Programming language designers and operating system designers have conflicting interests. The operating system designer wants to keep system calls as elementary as possible so that the operating system is reliable and secure, while the language designer wants to make tasks easy for the programmer. Thus, system calls tend to be very elementary, leaving it to the compiler to provide more sophisticated behavior through its libraries. The
printf()function is an example of this, where the library function provides complex formatting functionality, such as displaying numbers, that are not provided by any system calls (such aswrite, as we see below).
3. Linux file-handling
In Unix-based systems, a process can interact with files through file descriptors, integer identifiers of files that the process has open. For each process, the operating system maintains a table to track how file descriptors map to locations on the disk, but this table is not available for the process to see.
3.1. Managing descriptors
For creating a file descriptor, Linux has the open system
call, which takes two parameters, the file name and an int
representing options to the system call. The open system
call returns the integer file descriptor it creates, or a negative
number if the requested file can't be opened.
file_desc = open(filename, mode);The file name would be a pointer to the first character of a C string. The mode is an integer identifier for identifying how the program will use the file; for reading through a file, the right parameter value is 0.
The close system call allows a process to deallocate a file
descriptor.
close(file_desc);Closing a file is important in Linux for two reasons.
If the program changes the file's contents, the operating system will buffer the changes for efficiency reasons; it only writes the changes to the disk when the buffer becomes full. By closing the file, you are forcing the operating system to empty the buffer. Otherwise, if the program aborts abnormally, the changes don't occur.
The descriptor table maintained by the operating system has a limited size (such as 64). If you don't close your files, it can become full and a later
opensystem call will fail.
3.2. Reading and writing
To get information from a file, we use the read system
call.
nbytes = read(file_desc, buf, buf_len);This takes three parameters: first the file descriptor
(an int), then a pointer to an array of bytes (a
char*), and finally an integer saying how long the array is. It
returns an int representing the number of bytes read from the
file, 0 if it has reached the file's end, or a negative integer in the
case of an error.
The write system call is quite similar.
write(file_desc, buf, nbytes);It takes the file descriptor (an int), a pointer to an array of
bytes (a char*), and an integer saying how many bytes to write
to the file.
3.3. Examples
Below is a translation of a C program using some system calls.
int main() {
char buf[80];
int nbytes;
nbytes = read(0, buf, 80);
write(1, buf, nbytes);
exit(0);
}main MOV SP, #0x10000 ; set up stack
SUB SP, SP, #80 ; and allocate 80 bytes on it
MOV R0, #0 ; R4 = read(0, SP, 80)
MOV R1, SP
MOV R2, #80
SWI #3
MOV R4, R0
MOV R0, #1 ; write(1, SP, R4);
MOV R1, SP
MOV R2, R4
SWI #4
MOV R0, #0 ; exit(0);
SWI #1
Note the following about this program.
It subtracts 80 from the stack pointer to make room for the 80 bytes on the stack required for the array
buf. Then, when it callsread, it passes the value ofSPas the buffer pointer, since at this pointSPis pointing to the first character of the buffer. (Since the stack grows downward, and the array goes forward, the address of the stack's top is the beginning of the allocated array.)Note how it uses the return value of
readwhen after the interrupt returns, the program copiesR0intoR4.
The following longer program illustrates a program that uses
open and close in the process of copying from one
file to another. Notice how the program uses the constant
O_RDONLY to indicate that it is opening src.txt
for reading, and it uses O_WRONLY to
indicate that it is opening dst.txt for writing —
and it adds in O_CREAT to indicate that it should create
dst.txt if it doesn't already exist.
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int src_fd;
int dst_fd;
char buf[80];
int nbytes;
src_fd = open("src.txt", O_RDONLY);
if (src_fd < 0) {
printf("Could not open source file\n");
exit(-1);
}
dst_fd = open("dst.txt", O_WRONLY | O_CREAT);
if (dst_fd < 0) {
printf("Could not open destination file\n");
exit(-1);
}
nbytes = read(src_fd, buf, 80);
while (nbytes > 0) {
write(dst_fd, buf, nbytes);
nbytes = read(src_fd, buf, 80);
}
close(dst_fd);
close(src_fd);
exit(0);
}
3.4. Default descriptors
Every process has three file descriptors already defined for
it before it enters the program's main function.
0 represents standard input. Usually, reading from file descriptor 0 will correspond to reading data from the keyboard. This allows a process to receive input from the user.
1 represents standard output. Usually, characters written to 1 appear on the display.
2 represents standard error. Usually, characters written to 2 also appear on the display; the difference is that the system does not buffer the output as it does with standard output, and so any characters written appear immediately. This is meant for reporting errors, which the user should see immediately.
Notice that I said usually
in all of the above.
When you use redirection, the system
sets up the program's default file descriptors to have different
meanings. Suppose we wrote the following at a Unix prompt.
unix% a.out < infile > outfile
The system will interpret this command as saying to run the
a.out program, but make its 0 file descriptor refer to
infile instead of the keyboard, and make its 1 file
refer to outfile instead of the screen.
(It would keep the 2 file descriptor referring to the screen, so
any error messages sent to descriptor 2 by a.out would
still appear for the user to see.)
In fact, the program (a.out here) doesn't even know about
infile and outfile: it just reads from
file descriptor 0 and writes to file descriptor
1 as normal, oblivious to the fact that it's actually reading
from one file and writing to another.
The fact that file descriptors refer to files instead of the
keyboard and display is set up by the program that interprets
the users' commands and starts up programs; this program is
called the shell.
Because the shell handles redirection, redirection will work for any
program.
4. Processes
Today's sophisticated operating systems support the concept of a process, an instance of a program running on the computer. Processes don't really exist — you won't find them hiding out inside the computer somewhere — but they are one of the most useful abstractions that the operating system provides.
4.1. Process table
A classical CPU has only one thread of execution: That is, it does only
one instruction at at a time, which then tells it which
instruction to do next.
Nonetheless, at any time there are lots of processes in
existence (typically 100 or even more). The OS must provide each
process with the illusion that it owns
the computer. To do this,
the OS continually switches processes on and off the CPU. Because the
OS wants each process to believe that it has sole control over the CPU,
it must ensure that this switching is transparent. For example, each
process believes that it has sole control over the CPU's registers.
Thus, the OS must record each process's registers when switching it
off the CPU, and it must restore the registers when it returns the
process to the CPU.
(In fact, modern CPUs can execute instructions simultaneously, as in pipelined, superscalar, and especially multicore chips. On the whole, though, the CPU works hard to provide the illusion that it completes one instruction at a time, and so it's reasonably safe for us to assume that this is in fact how it works.)
To store information about where each of the processes is, the OS maintains a process table internally. The process table stores what the OS needs to remember for each process. In Unix, each process gets a process ID. This is the index into the process table, which is an array of structures. Each process table entry contains the following information (among other things):
- the process's status.
- the process's last observed program counter value, so the operating system knows from where it should continue when the program begins running on the CPU next time.
- the process's last observed register values, so they can be restored when the process is to run again.
- the process's file descriptor table.
- a pointer to the next process in line.
4.2. Context switching
During a process's life, it goes through three states: It can be running on the CPU, it can be ready for the CPU, or it can be blocked.
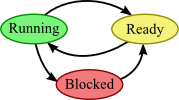
Suppose that a process is currently running on the CPU, but then it gets to a point that it wants to retrieve some data from an I/O device like the disk. In this case, the operating system will move the process from the running state to the blocked state, and promote some ready process into the running state instead. This is called a context switch, and it proceeds as follows.
- The running process sends a system call via an interrupt.
- The CPU jumps into the interrupt handler, which is part of the operating system.
- The OS saves all the registers of the running process into that process's entry of the process table.
- If another process is already waiting for the device to respond, the OS places the process into a waiting queue for that device. Otherwise, the process's request is sent to the device.
- The OS selects the next process to execute from the queue of those processes in the ready state. This is called the ready queue.
- The OS restores the registers to the values saved in the next process's entry of the process table.
- The OS returns to the program counter value stored in the next process's entry of the process table.
This whole sequence corresponds to the arrow from the Running state to the Blocked state for the requesting process, plus the arrow from the Ready state to the Running state for the selected next process.
Much later, when the device has found the requested data, it will send a hardware interrupt to the CPU. This interrupts whichever process is currently running, and the CPU begins instead executing the OS's interrupt handler. The handler proceeds as follows.
- The OS saves the device's response in memory for the requesting process to use when it gets the CPU again.
- The OS moves the blocked process into the ready queue.
- If there are processes waiting for the device, the OS sends the next request to the device.
- The OS returns back to the process that was running at the time the interrupt occurred.
This process corresponds to the arrow from the Blocked state to the Ready state.
4.3. Preemption
Operating systems today usually support the concept of preemption, where the operating system will cut off a process after it uses the CPU for a certain amount of time (called its time slice) and put it back into the ready queue. This is represented by the arrow from the Running state to the Ready state in the state diagram.
Accomplishing this isn't completely straightforward. The CPU dedicates itself to executing whatever code sequence it is tasked to perform. Thus, if it is in the midst of executing the code for a process, then it isn't executing any OS code, and so the OS can't take any actions, including the action of removing the running process from the CPU. The OS needs some way of regaining control.
To permit this, computer systems incorporate a clock device, a device with which the OS can schedule a hardware interrupt to occur after a certain amount of time. The OS may tell the clock device to send an interrupt to occur every, say, 10 ms; this interrupt will transfer the CPU into the interrupt handler, which is part of the operating system, and the handler can take the currently running process off the ready queue.
It's important to remember that context switching isn't a quick job for the CPU. It takes time to go through the context switching process. Thus, preempting processes actually makes the system complete jobs more slowly.
Operating systems tend to find preemption worthwhile anyway because of the convenience to the user of seeing all processes making progress at all time, and because processes that take a lot of CPU time are generally less urgent: If a process runs for a long time, the user is already obligated to wait, so a few more seconds won't hurt. Spending time to delay such a process is worthwhile if it means running another process requiring less computation, for which the user may well be waiting.
4.4. Process scheduling
When the ready queue contains many processes, and it's time to choose one to start running, the OS is in a dilemma: Which one to select? This selection process is called process scheduling, and researchers have given it much attention.
The simplest process scheduling algorithm is round robin, in which each process is treated equally. When one process runs its time slice out, it is simply placed at the end of the ready queue, and the next process in line begins.
But systems frequently do something more complex. For example, many have some concept of priorities assigned to processes. In some systems, a process with a higher priority is always chosen over a process with a lower priority, but this situation can easily starve out the low-priority jobs. To avoid this, a system might assign longer time slices to higher-priority jobs, but otherwise follow a round-robin strategy. Or a system might choose jobs probabilistically, where higher-priority jobs have a higher priority of being selected.
5. Linux process management
The operating system must provide some support for managing processes. We'll look at the system calls supported by Linux toward this purpose.
One of them we have already seen: the exit system
call, which allows a process to request that it be killed.
void exit(int exit_code)5.1. Creating processes
But there should also be some way for a process to start new
processes. In Linux, this is accomplished with the fork system
call.
int fork()The fork system call creates a duplicate of the currently
running process. It is a complete clone — it has a new process ID, but
the process table entry for the current process is copied into
the clone's process table entry. It
has its own memory space, but all the memory of the previous process is
copied into the clone's memory also.
Thus, the old parent
process and the new child
process are
indistinguishable, except for the process IDs.
They even both continue from the fork system call, since
they have the same program counter values and the same memory
values.
But there is one key difference (beyond the different process IDs):
The fork system call returns different numbers to the two
processes. It returns 0 to the child process, and it returns the child
process's process ID to the parent process.
It sounds a bit confusing. Let's look at an example program
that illustrates the fork system call.
#include <stdio.h>
#include <unistd.h>
int main(int argc, char **argv) {
int remaining = 4;
int child_pid;
/* spawn off children */
while (remaining > 0) {
child_pid = fork();
if (child_pid == 0) break;
remaining--;
}
printf("hello\n");
return 0;
}
What this program does is create four child processes, and the parent process and each of the four child processes print the word hello to the screen. (Creating processes to do this job is a bit contrived. But we need a simple example to examine.)
When this process begins, it sets the remaining variable at
4, and it gets to the fork system call. At this point, there
are two identical processes. In the child process, the fork
system call returns 0, and so child_pid is 0, and the
process child out of the loop and prints hello.
In the parent process, the fork system call returns a process
ID, which is not 0, and so it continues through the loop and executes
the fork system call again, spawning another child, and again,
spawning another child, and finally a fourth time, at which
point remaining reaches 0 and the parent process displays
hello.
If you were to run this program, then, it would print hello five
times. All the five processes would be vying to print to the
screen virtually simultaneously, however, and so you might see the
following under some systems. (In practice, this could be
impossible, since printf would pass the 6-letter sequence
into write, which might then treat the 6-letter sequences as a
group processed together.)
helhelhole llloho heel lol lo
5.2. Running programs
Sometimes we will want to run a different program
entirely. For this, you can use the execvp system
call.
int execvp(char *file, char **args)The first parameter to execvp is a filename of the executable
file that the operating system is to execute. The second parameter
should contain a pointer to an array of pointers to the various
command-line arguments to be
passed into it (via the main function, for example).
The last element of the array should be NULL, so that the
system can determine how many command-line arguments there
are.
When the system executes the execvp system call, it replaces
the program run by the current process with the requested program.
That is, the current process — which was executing a
program that included an invocation of execvp —
switches from executing that program to executing a different
program entirely.
Thus, execvp, when it is working correctly, does not return.
Instead, the process's execution thread is transferred to the beginning
of the requested program.
5.3. A simple shell
Under Unix systems, the program that reads user commands and starts programs is not really part of the operating system. It is called the shell, and it runs as a regular user program. In fact, there is no reason that you can't write your own and run it. In fact, the below program does that, illustrating how the process management system calls combine together to get a genuinely useful program.
#include <unistd.h>
#include <sys/wait.h>
#define CMD_LEN 120
int main(int argc, char **argv) {
char cmd[CMD_LEN];
char *cmd_args[2];
int n;
int child_pid;
while (1) {
/* read command from user */
write(1, "% ", 2);
n = read(0, cmd, CMD_LEN);
if (n == 0) break; /* EOF reached; exit program */
cmd[n - 1] = '\0'; /* replace '\n' with '\0' */
/* fork off child to execute command */
child_pid = fork();
if (child_pid == 0) {
cmd_args[0] = cmd;
cmd_args[1] = NULL;
execvp(cmd, cmd_args);
/* If execvp returns, the command is bad. */
write(1, "Command not found\n", 19);
exit(-1); //@ child1
}
/* wait for child to exit before continuing */
waitpid(child_pid, &n, 0);
}
return 0;
}
This program uses another system call called waitpid, which
a program can use to wait until a process completes its task.
The waitpid system call requires three parameters, one to
specify which process to wait for; another is an int* saying
where to store the process's exit code; and the last parameter is for
options (0 is fine here).
int waitpid(int pid, int *status, int options)This program is an infinite loop.
Each iteration begins by reading a command from the user in
the first four lines of the loop.
Then the shell forks off a process
with
.
Two processes continue to the child_pid = fork();if statement following.
For the child process, the fork system call returns 0, and so
the child process executes the if statement's body,
which executes the execvp system call to replace the child
process with the program given by the user's command.
For the parent process,
the fork system call returns the created child's process ID.
The parent process executes the waitpid system call,
which stalls the process until the child completes running,
whereupon the parent will continue to the next iteration, which reads
and processes the next command from the user.