In the 1950's, the American linguist Noam Chomsky considered the following question: What is the structure of language? His answer turns out to form much of the foundation of computer science. In this chapter, we examine a part of this work.
One of the first steps to exploring linguistic structure, Chomsky decided, is to define our terms. Chomsky chose a mathematical definition: We define a language as a set of sequences chosen from some set of atoms. For the English language, the set of atoms would be a dictionary of English words, and the language would include such word sequences as the following.
this sequence contains five atoms
lend me your ears
what does this have to do with computer science
Though the language of all possible English sentences is quite large, it certainly does not include all possible sequences of atoms in our set. For example, the sequence
rise orchid door love blue
would not be in our language. Each sequence in the language is called a sentence of the language.
This definition of language is mathematical, akin to defining
a circle as the set of points equidistant from a single point.
Notice that it is general enough to allow for nontraditional languages,
too, such as the following three languages.
Our atoms could be the letters a and b, and our language could be the set of words formed using the same number of a's as b's. Sentences in this language include ba, abab, and abbaab.
Our atoms could be the decimal digits, and our language could be the digit sequences which represent multiples of 5. Sentences in this language include 5, 115, and 10000000.
Our atoms could be the decimal digits, and our language could be the digit sequences which represent prime numbers. Sentences in this language include 31, 101, and 131071.
In analyzing linguistic structure, Chomsky came up with a variety of systems for describing a language, which have proven especially important to computer science. In this chapter, we'll study one of the most important such systems, context-free grammars. (Chomsky called them phrase structure grammars, but computer scientists prefer their own term.)
A context-free grammar is a formal definition of a language defined by some rules, each specifying how a single symbol can be replaced by one of a selection of sequences of atoms and symbols. (The term context-free refers to the fact that each rule describes how the symbol can be replaced, regardless of what surrounds the symbol (its context). This contrasts it with the broader category of context-sensitive grammars, in which replacement rules can be written that only apply in certain contexts.)
We'll represent symbols using boldface letters and the atoms using italics. The following example rule involves a single symbol S and a single atom a.
S → a S a | a
The arrow →
and vertical bar |
are for
representing rules.
Each rule has one arrow (→
).
On its left side is the single symbol which can be replaced by a
sequence.
There can be several alternatives for sequences that can replace
it; these alternatives are listed on the
arrow's right side, with vertical bars (|
) separating the
alternatives.
We can use this example rule to perform the following
replacements.
S ⇒ a S a replace S with the first alternative, a S a. a S a ⇒ a a S a a replace S with the first alternative, a S a. a a S a a ⇒ a a a a a replace S with the second alternative, a.
A derivation is a sequence of steps, beginning from the symbol S and ending in a sequence of only atoms. Each step involves the application of a single rule from the grammar.
S ⇒ a S a ⇒ a a S a a ⇒ a a a a a
In each step, we have taken a symbol from the preceding line and replaced it with a sequence chosen from the choices given in the grammar.
A little bit of thought will reveal that this grammar (consisting of just the one rule S → a S a | a) allows us to derive any sentence consisting of an odd number of a's. We would say that the grammar describes the language of strings with an odd number of a's.
Let's look at a more complex example, which describes a small subset of the English language.
S → NP VP NP → A N | PN VP → V | V NP A → a | the N → cat | student | moon PN → Spot | Carl V → sees | admires
This context-free language consists of many rules and symbols. The symbols — S, NP, VP, A, N, PN, and V — stand, respectively for sentence, noun phrase, verb phrase, article, noun, proper noun, and verb.
We can derive the sentence, the cat sees
Spot
using this context-free grammar.
S ⇒ NP VP ⇒ A N VP ⇒ A N V NP ⇒ the N V NP ⇒ the N sees NP ⇒ the cat sees NP ⇒ the cat sees PN ⇒ the cat sees Spot
(When you perform a derivation, it's not important which symbol you choose to replace in each step. Any order of replacements is fine.)
In many cases, it's more convenient to represent the steps leading to a sentence described by the grammar using a diagram called a parse tree.
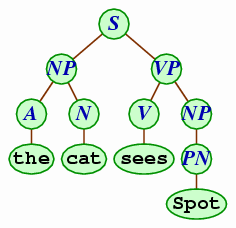
A parse tree has the starting symbol S at its top. Every node in the tree is either a symbol or an atom. Each symbol node has children representing a sequence of items that can be derived from that symbol. Each atom node has no children. To read the sentence described by the tree, we read through the atoms left to right along the tree's bottom fringe.
Other sentences included in this grammar include the following.
a cat admires
Spot sees the student
the moon admires Carl
Proving that each of these are described by the grammar is relatively easy: You just have to write a derivation or draw a parse tree. It's more difficult to argue that the following are not described by the grammar.
cat sees moon
Carl the student admires
A context-free language is one that can be described by a context-free grammar. For example, we would say that the language of decimal representations of multiples of 5 is context-free, as it can be represented by the following grammar.
S → N 0 | N 5 N → D N | λ D → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
(We use λ (the Greek letter lambda) to represent the empty sequence; this is just to make it clear that the space is intentionally blank.)
Often the fact that a language is context-free isn't immediately obvious. For example, consider the language of strings of a's and b's containing the same number of each letter. Is this language context-free? The way to prove it is to demonstrate a context-free grammar describing the language. Thinking of a grammar for this language isn't so easy. Here, though, is a solution.
S → a S b S | b S a S | λ
To get a feel for how this grammar works, we look a derivation (and corresponding parse tree) for the string aabbba according to the grammar. (The derivation is augmented by underlining the symbol to be replaced in the following step.)
S ⇒ a S b S ⇒ a a S b S b S ⇒ a a S b b S ⇒ a a b b S ⇒ a a b b b S a S ⇒ a a b b b S a ⇒ a a b b b a 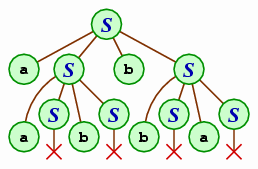
A single example isn't enough to convince ourselves that this grammar works, however: We need an argument that our grammar describes the language. In this case, the argument proceeds by noting that if the string begins with an a then there must be some b so that there are the same number of a's and b's between the two and there are the same number of a's and b's following the b. A similar argument applies if the string begins with a b. We'll skip over the details of this argument.
Now consider the language of strings of a's, b's, and c's, with the same number of each. Is this context-free? To test this, we can look for a context-free grammar describing the language. In this case, however, we won't be successful. There is a mathematical proof that no context-free grammar exists for this language, but we won't look at it here.
We can now apply our understanding of context-free languages to the complex languages that people use.
Chomsky and other linguists are interested in human languages, so the question they want to answer is: Are human languages context-free? Chomsky and most of his fellow American linguists naturally turned to studying English. They have written thousands of rules in an attempt to describe English with a context-free grammar, but no grammar has completely described English yet. Frustrated with this difficulty, they have also tried to look for a proof that it is impossible, with no success there, either.
Other languages, however, have yielded more success. For example, researchers have discovered that some dialects of Swiss-German are not context-free. In these dialects, speakers say sentence like
Claudia watched Helmut let Eva help Hans make Ulrike work.
with the following word order instead. (Of course, they use Swiss-German words instead!)
Claudia Helmut Eva Hans Ulrike watched let help make work.
The verbs in this sequence are in the same order as the nouns to which they apply. Swiss-German includes verb inflections, and each verb inflection must match with its corresponding noun, just as English requires that a verb must be a singular verb if its subject is singular.
To prove that this system isn't context-free, researchers rely on its similarity to an artificial language of strings with a's and b's of the form X Y, where X and Y are identical. There is a mathematical proof that this artificial language is not context-free, and the proof extends to Swiss-German also.
There are very few languages that researchers know are not context-free, but their existence demonstrates that the human brain can invent and handle such complex languages. This fact, coupled with the tremendous difficulty of accommodating all of the rules of English into a single context-free grammar, leads many researchers to believe that English is not context-free either.
On the other hand, programming language designers intentionally design their languages so that programmers can write compilers to interpret the language. One consequence is that programming languages tend to be context-free (or very close to it). Indeed, compilers are usually developed based on the context-free grammar for their language.
As an example, the following is a grammar for a small subset of Java.
S → Type run ( ) { Stmts } Stmts → Stmt Stmts | λ Stmt → Type Ident = Expr ; | Expr ; | while ( Expr ) Stmt | { Stmts } Expr → Expr + Expr | Expr - Expr | Ident > Expr | Ident = Expr | Ident | Num Type → String | int | void | Type [] Ident → x | y | z Num → 0 | 1 | 2 | 3 | 4
Consider the following Java fragment.
void run() {
int y = 1;
int x = 4;
while(x > 0) {
x = x - 1;
y = y + y;
}
}
This fragment is a sentence generated by our grammar, as illustrated by the parse tree below.

Of course, this grammar covers a small piece of Java. The grammar for all of Java has hundreds of rules. But such a grammar has been written, and the compiler uses this grammar to break each program into its component parts.
Throughout this discussion, the distinction between syntax and semantics is important. Syntax refers to the structure of a language, while semantics refers to the language's meaning. Context-free grammars only describe a language's syntax. Semantics is another story entirely.
For natural languages, the line separating syntax and semantics is
somewhat fuzzy.
For example, English has a rule that the gender of a pronoun should
match the gender
of its antecedent. It would be improper for me to say, Alice
lifts himself up,
assuming Alice is female.
Most linguists would argue that this is a matter of semantics, as it
requires knowledge of the meaning of Alice.
They would argue, however, that the issue of subject-verb
agreement is a syntactic issue.
(An example where the subject and verb do not agree is
We hates the hobbit
: Since we is plural,
the verb should be hate.)
For programming languages, people generally categorize issues surrounding the generation of a parse tree as syntactic, while others are semantic. The rule that each variable declaration must end in a semicolon, however, is a syntactic rule.
The process of taking a program and discerning its structure is
called parsing. Thus, you will sometimes see a compiler complain
about a parse error.
For compilers built around a context-free
grammar, this indicates that your program doesn't fit into the language
described by its grammar.