So far we've thought about how to use dictionaries. While you can write quite useful programs with this knowledge, it only seems fair that you might know how they actually work.
Our discussion has presented dictionary as basically a list of key-value pairs. Suppose we have the following code:
zips = {}
zips[60606] = 'Chicago'
zips[72032] = 'Conway'
zips[20500] = 'DC'
zips[10118] = 'NYC'
zips[98109] = 'Seattle'
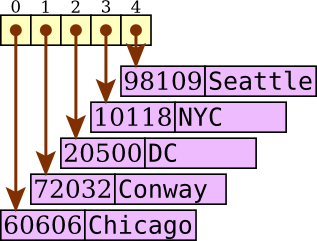
We could represent a dictionary like zips as a list
of key-value pairs. You can imagine each key-value pair as
itself a list with just two elements, the first holding the key
and the second holding the corresponding value.
When we want to look up a value associated with
a key (as in “print(zips[72032])”),
we would step through each entry of the list, seeing
whether the key for that entry matches and if so retrieving the
corresponding value.
While dictionaries could be implemented that way, in practice this technique is quite slow. Real-life dictionaries often have thousands or even millions of key-value pairs. If we used this list-based technique, then the computer would have to step through all of the key-value pairs each time we did a lookup.
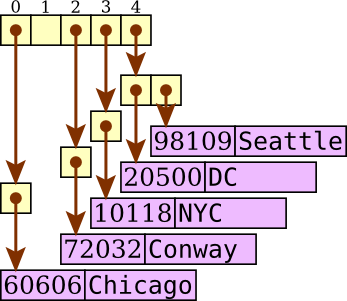
To improve efficiency, we use buckets: Each bucket is a list as illustrated above, and the dictionary is a list of these buckets.
Suppose we were to do our example with seven buckets. When we want to add a key-value pair, we must first determine which of the seven buckets should contain that pair. To do this, we'll use the remainder when the key is divided by seven (the number of buckets). We end up with the following representation.
For example, in adding the 60606-Chicago pair, we compute
60606 % 7 and find that the remainder is 0, so we add
the pair into bucket 0. Similarly, the 20500-DC pair ends up in
bucket 4, as does the 98109-Seattle pair.
Now when we have a statement like
“print(zips[72032])”, we determine which
bucket would contain 72032 by computing 72032 % 7, which
is 2. We then search through bucket 2 to find the key 72032.
In this case, we end up going straight to the desired key-value pair;
in general, we may have to examine each key in the bucket.
Of course, the bucket may have several keys to examine. But this is substantially faster than the list-based technique described earlier: Before, we may end up having to search all keys. But you'd expect each bucket to have only one seventh of the keys (assuming that keys distribute evenly across buckets), so you'd expect this technique to be seven times as fast as before.
Of course, if our dictionary has a million items, dividing the million items among seven buckets still results in some very large buckets to search! To avoid this, we grow the number of buckets as the number of items added grows. For example, once the number of items reaches the number of buckets, we might double the number of buckets. Of course, doubling the number of buckets means that we have to redistribute everything into buckets anew, which takes quite a bit of time; but it will take quite a while before we have to double again, and even longer before the next doubling, so it basically averages out to not be too bad.
You might wonder: Why not just avoid multi-item buckets altogether by doubling the number of buckets whenever we have two things that belong to the same bucket? This is impractical due to the birthday paradox, a somewhat surprising probabilistic fact that if you have 23 people in the same room, chances are some two of them share the same birthday. That means that if we had 365 buckets, and if we insisted that we double the buckets each time we have a collision, then we would need to double the buckets once we reached around 23 keys. We'd double again once reaching around 33 keys, then around 45. The doublings are just too frequent, and we end up using far more memory than necessary.
So far, we have worked with dictionaries where the keys are integers, and we could map an integer to a bucket by just finding the remainder when the integer is divided by the number of buckets.
But what if the keys are a different type, like a string?
In that case, we use a hash function: A function that
takes a key and maps it to an integer. So, given a string, what
function might we use that gives us an integer? One might think
of the len function: It gives an integer for any
strings. But if we have a dictionary using English words as keys, we would
find that just about everything maps into buckets 3 through 10,
even if there are 10,000 keys.
We prefer a hash function that usually gives different integers for different strings. One popular function is the following, using ci to represent the integer corresponding to the ASCII/Unicode code for character i of the string; for example, for the string a, c0 would be 97.
∑i 31i ci = c0 + 31 ⋅ c1 + 31² ⋅ c2 + 31³ ⋅ c3 + …
If you change a string slightly, it's quite unlikely this will end up getting the same value. So this works well as a hash function.
(Python uses a similar idea to this — though using 1000003 rather than 31 and making a few other minor tweaks.)