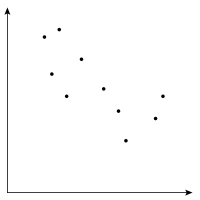
Clustering is an important problem that comes in many contexts, including search results, advertising, and politics: We have a set of points, and we want to break them up into a handful of “clusters” of near neighbors. For example, suppose we have 10 points on the plane.
And suppose we want to identify two different “clusters” to which each point belongs. In this particular picture, it might make sense to see that the lower right group of points are part of one cluster while the upper left group of points belong to another cluster.
To see how this might be applied to advertising, say, the points might represent customers. Each coordinate might represent things that the customers have bought in the past. For instance, maybe the x-axis represents how many groceries the customer has bought, while the y-axis represents how many books the customer has bought. We might suppose that we want to identify groups of customers, so we can advertise one sale to customers in one cluster but a different sale to customers in another cluster. After all, a sale on baby bottles may be very attractive to customers who seem to buy diapers, but hardly attractive to others.
In such a context, you might expect each point to be across hundreds of dimensions (each representing a different product), you might expect there to be thousands of points, and you might want to separate the thousands of points into a dozen or so different clusters. For the sake of having a sane example that we can picture, though, we'll stick to our 10 points in two-dimensional space, which we want to separate into two different clusters.
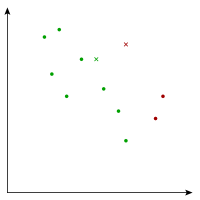
The k-means algorithm, also known as Lloyd's algorithm, is a popular technique for this. First we choose two “centers” randomly.
After choosing two random centers, which I've diagrammed as red and green X's above, for each point we figure out which center is closest. In the above diagram, I've colored each point red or green to illustrate which center it is closest to.
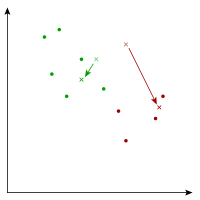
After breaking our points into two groups, we then take the center among each group, and we move the “center” to this computed center.
As you can see, after moving each center, some points that were previously closer to one center have become closer to another instead. We repeat the process.
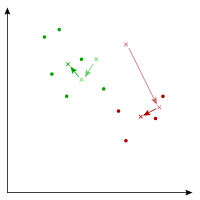
In general, we continue repeating the process until the centers don't seem to be moving far. In this simple example, though, we are done: No points moved from one center to another, so there won't be any more movement.
As you can see, we've ended up with a situation where the lower right points have been identified as belonging to a separate cluster from the upper left points, just as we expected.
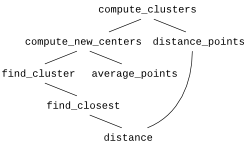
The k-means algorithm is interesting because it is both (a) important and (b) reasonably complex. In fact, at first it may look way too complex for a beginner. But using functions, we can break it down to bite-sized pieces that we can reasonably tackle. Here are some helpful functions:
distance(x0, y0, x1, y1)Computes and returns the distance from (x0, y0)
to (x1, y1).
find_closest(x0, y0, centers)Computes and returns the index of which point in centers
is closest to (x0, y0).
(In this and the following, when we have a list of points like
centers, it is actually a list of lists: Each sublist
represents a point, and it contains two numbers corresponding to
the point's x-coordinate and the point's
y-coordinate.
(This function will end up using distance.)
find_cluster(index, centers, points)Computes and returns a list of the points in points
that are closest to center index from centers.
(This function will end up using find_closest.)
average_points(points)Computes and returns the point whose
x-coordinate is the average of the
x-coordinates in points and whose
y-coordinate is the average of the
y-coordinates in points.
distance_points(points0, points1)Computes and returns the total distance
between corresponding points in points0 and
points1
(This function will end up using distance.)
From here, we can define a function that computes the next set of centers based on the current set of centers.
def compute_new_centers(centers, points):
result = []
for i in range(len(centers)):
cluster = find_cluster(i, centers, points)
center = average_points(cluster)
result.append(center)
return result
And then we can define a function that handles the entire k-means clustering algorithm:
def compute_clusters(points, num_clusters):
centers = []
for i in range(num_clusters):
centers.append([100 * random.random(), 100 * random.random()])
while True:
new_centers = compute_new_centers(centers, points)
if distance_points(new_centers, centers) < 0.001:
return new_centers
centers = new_centers
Here, the first for loop just generates the initial
randomly generated points. Then for 1,000 iterations we update
to a new set of centers. It may be that this process slow down
much faster, so most of the iterations may be pointless
repetition; but 1,000 iterations will likely be enough
to settle down to a reasonable group of centers.
Look at what happened here: In order to develop a very complex algorithm, we broke the problem into relatively simple problems, each of which fit into a function. This is called decomposing a problem.
We can visualize how the different functions here use one another.