[1] [2] [3] [4] [5] [6] [7] [8] [9]
[6 pts] If we store Unicode characters as separate 16-bit sequences, roughly how many Unicode characters can be stored in a one megabyte file?
Roughly 500,000 (actually, 524,288 exactly), since a megabyte is roughly 1,000,000 bytes and each Unicode character is two bytes long (16 bits is two bytes).
[8 pts]
What single value for template would result in the following strings
being produced? (Don't include the quotes.)
template.format(98, 24.5) | → | “98/4 = 24.50” |
template.format(7, 1.75) | → | “ 7/4 = 1.75” |
{0:2d}/4 = {1:5.2f}”
[6 pts] Write a regular expression for all sequences of 0's and 1's in which an adjacent pair of 0's appears somewhere before an adjacent pair of 1's. Examples include 0011, 101000101110, and 1100011, but not 1010101 or 10110010.
[01]*00[01]*11[01]*
[8 pts] Suppose we were to use binary search to check whether 11 is in the following list.
0, 3, 5, 7, 9, 11, 12, 17, 19, 21, 23, 27, 29, 33, 34
List the integers from the list that binary search would examine, in the order they are examined.
17, 7, 11.
lo hi mid check 0 14 7 17 0 6 3 7 4 6 5 11
[10 pts]
Suppose the file pops.txt is a tab-separated values
file, where each line contains three values: a city name, a
state name, the city's current population, and the city's
population three years ago. Here are five example lines from the
file.
Chicago Illinois 9899902 9840929
Los Angeles California 18238998 17877006
New York New York 23362099 23076664
San Francisco California 8370967 8153696
Washington DC 9331587 9051961Write a program to display how many cities in the file have shrunk in population over the last three years — that is, how many lines have the third column being less than the fourth column.
infile = open('pops.txt')
num_shrink = 0
for line in infile:
parts = line.rstrip().split('\t')
new_pop = int(parts[2])
old_pop = int(parts[3])
if new_pop < old_pop:
num_shrink += 1
print(num_shrink)
[8 pts] Suppose we have the same file as in the previous question, and we want a program that displays each state name followed by the name of the largest city in that state. Describe how a program could do this while reading through the file just once. Your answer may use Python code, or you may describe in English the key variables you would need, what the variables represent, and how you would update them as you go through each line of the file.
Have one variable that is a dictionary mapping state names to the largest population found so far within the state, and another that is a dictionary mapping state names to the city with the largest population found so far within the state.
As we go through each line, we'll split it into its four
component parts and compare the population to the previous best
population for the state (retrieved using
“max_pop.get(state, 0)”); if the current
line shows a larger population, we store the population into
that dictionary while at the same time updating the city name
for that state in the other dictionary.
After we've processed the file, we would step through each key in the second dictionary and display the state name (the key) and the corresponding city.
infile = open('pops.txt')
max_pop = {}
max_city = {}
for line in infile:
parts = line.rstrip().split('\t')
city = parts[0]
state = parts[1]
pop = int(parts[2])
if pop > max_pop.get(state, 0):
max_pop[state] = pop
max_city[state] = city
for state in sorted(max_city.keys()):
print('{0:15s} {1}'.format(state, max_city[state])
[12 pts] Below in the skeleton of an implementation of selection sort for a list of numbers. Fill in the missing pieces.
def selection_sort(nums):
for i in range(len(nums) - 1):
minval = nums[i]
minloc = i
# find smallest value in nums[i:] as minval and that value's index as minloc
# swap nums[i] and nums[minloc]
def selection_sort(nums):
for i in range(len(nums) - 1):
minval = nums[i]
minloc = i
# find smallest value in nums[i:] as minval and that value's index as minloc
for j in range(i + 1, len(nums)):
if nums[j] < minval:
minval = nums[j]
minloc = j
# swap nums[i] and nums[minloc]
t = nums[i]
nums[i] = nums[minloc]
nums[minloc] = t
[12 pts]
Without using loops or any built-in functions except sum
and len, write a recursive function named
suffix_sums that takes a list of numbers as a parameter and
returns a list in which each entry corresponds to the sum of the
corresponding and later entries in the parameter list.
For example, if primes is [2, 3, 5, 7, 11],
then suffix_sums(primes) should return the list
[28, 26, 23, 18, 11]: We have 28 in the first slot
because it is the sum of all numbers in primes, we have
26 in the second slot because it is the sum of all but the first
number in primes, and so on.
def suffix_sums(nums):
if len(nums) <= 1:
return nums
else:
first = sum(nums)
rest = suffix_sums(nums[1:])
return [first] + rest
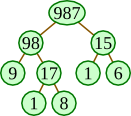
[10 pts]
Draw a recursion tree representing the recursive calls made when
computing the value of f(987) using the following
function.
def f(n):
if n < 10:
return n
else:
ones = n % 10
rest = f(n // 10)
return f(ones + rest)